概要
本文提出了针对强化学习的对抗性攻击,然后借助这些攻击提高深度强化学习算法对参数不确定性的鲁棒性。 这种针对DRL算法的对抗性训练,如Deep Double Q学习和Deep Deterministic Policy Gradients,可以显著提高RL基准的参数变化的稳健性。
简介
本文提出了两个贡献点:首先,本文提出了一个特定于强化学习设置的目标函数,这个函数的优化降低了RL算法的性能。旨在利用该目标函数的最小值的攻击确保受到攻击的RL智能体被欺骗,使之认为它处于导致其当前状态下采取最坏可能动作的状态。作者观察到,与DRL相比,线性参数化RL算法对于这种对抗性攻击具有更强的鲁棒性。其次,本文的方法提高了DRL算法对参数不确定性的鲁棒性。作者使用所提出的工程对抗攻击来训练DRL,并表明它在各种参数中表现出显着的性能改善。
相关工作对比
- 与Huang等人的方法相比,本文中提出的损失函数可以保证最大化采取最坏可能行为的概率,而Huang等人的方法并不一定如此。
- 与Lin等人的方法相比,受过训练的智能体的价值函数本身包含有关这种可能的最差行动序列的信息,而本文使用价值函数来寻找对抗行动,而不是试图遵循另一个随机的行动序列。
- Huang与Lin等人的方法都是基于图像,也就是高维度的输入,而本文提出的方法不仅限于高维图像。
- Rajeswaran等人的方法对模型参数进行采样并使用这些参数变化执行轨迹展开,然后基于最差执行百分位标准选择参数以进行训练。然而,具有不确定参数的采样轨迹可能存在风险。而且,对于大量参数,采样可能非常困难。本文则提出了可以直接提取最差表现轨迹的方法。
攻击方法
简单对抗攻击
作者提出了一种产生对抗性攻击的简单方法。 这种攻击背后的想法是产生随机噪声,进行采样并将其添加到当前状态,希望优选出的噪声样本将导致智能体采取“坏”操作,即次优动作。攻击质量可以通过值函数确定。 攻击是在评估阶段产生的。对抗性攻击本质上是对附近观察的搜索,这将导致智能体采取错误行动。在每次迭代期间不会产生一次噪声,而是每次迭代都会对其进行多次采样,以寻找最佳的对抗性噪声,导致值函数的最小估计的特定噪声被选择为对抗性噪声。
DDQN

DDPG

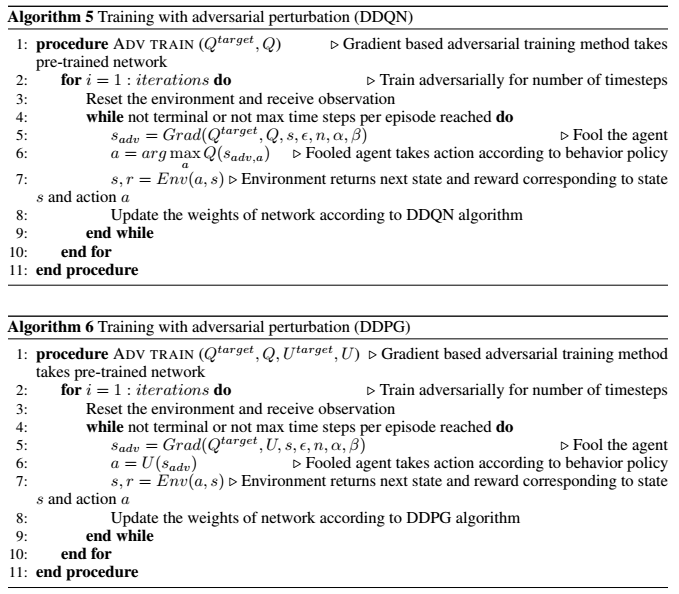
基于梯度的对抗攻击
本文给出的这个方法可以比传统的FSGM方法更快地找到最差的动作选择。下面的定理1给出了需要优化的目标函数,可以证明,该函数的最小化会使得对抗攻击最优。

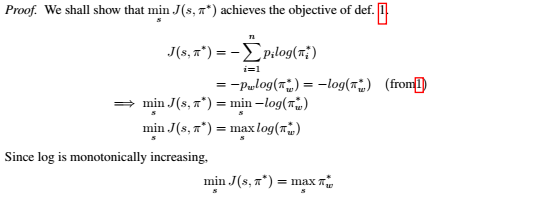 因此,我们已经证明了应该用于RL算法攻击的目标函数应该由定理1给出。这个目标函数不同于Huang等人提到的目标函数。Huang等人的目标函数会导致采取最佳行动的可能性降低。但这种方法不一定会导致采取最坏行动的可能性增加。
因此,我们已经证明了应该用于RL算法攻击的目标函数应该由定理1给出。这个目标函数不同于Huang等人提到的目标函数。Huang等人的目标函数会导致采取最佳行动的可能性降低。但这种方法不一定会导致采取最坏行动的可能性增加。
DDQN

DDPG

基于SGD的攻击
本文还使用随机梯度下降方法进行对抗攻击,不是采样几次并在这些样本中选择最佳可能的攻击,而是遵循相同数量的采样时间的梯度下降,并选择最终作为对抗状态的状态。
通过鲁棒控制框架进行对抗性训练
考虑到转换模型的一系列问题如需要知道高参数、模型可能会变化等,本文中使用的优化目标定义如下:
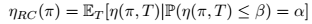 因此,问题归结为最大化α 个百分点回报的预期回报。此后,为了对这些不良轨迹进行采样,有通过执行具有不同参数的展示来更改过渡模型参数和样本轨迹的,有采用对手施加控制行动并试图将RL智能体推入可能的坏状态的。 但这两种方法很难找到均衡情况。本文采取直接的方法,对手欺骗智能体相信它处于与实际状态不同的“傻瓜”状态,“傻瓜”状态中的最佳动作会导致实际的当前状态下采取最差的动作。 换句话说,对手欺骗智能体直接采样最差轨迹。本文首先使用DDQN或DDPG训练算法,然后训练有素的智能体通过对抗训练来模拟不确定性。 本文使用基于梯度的攻击进行对抗训练,因为它在所有攻击中表现最佳。在本文的方法中,最差的α百分位数的回报与对抗性攻击的幅度有关,较高的对手幅度对应于较高的α最差百分位数的优化。
因此,问题归结为最大化α 个百分点回报的预期回报。此后,为了对这些不良轨迹进行采样,有通过执行具有不同参数的展示来更改过渡模型参数和样本轨迹的,有采用对手施加控制行动并试图将RL智能体推入可能的坏状态的。 但这两种方法很难找到均衡情况。本文采取直接的方法,对手欺骗智能体相信它处于与实际状态不同的“傻瓜”状态,“傻瓜”状态中的最佳动作会导致实际的当前状态下采取最差的动作。 换句话说,对手欺骗智能体直接采样最差轨迹。本文首先使用DDQN或DDPG训练算法,然后训练有素的智能体通过对抗训练来模拟不确定性。 本文使用基于梯度的攻击进行对抗训练,因为它在所有攻击中表现最佳。在本文的方法中,最差的α百分位数的回报与对抗性攻击的幅度有关,较高的对手幅度对应于较高的α最差百分位数的优化。
结果
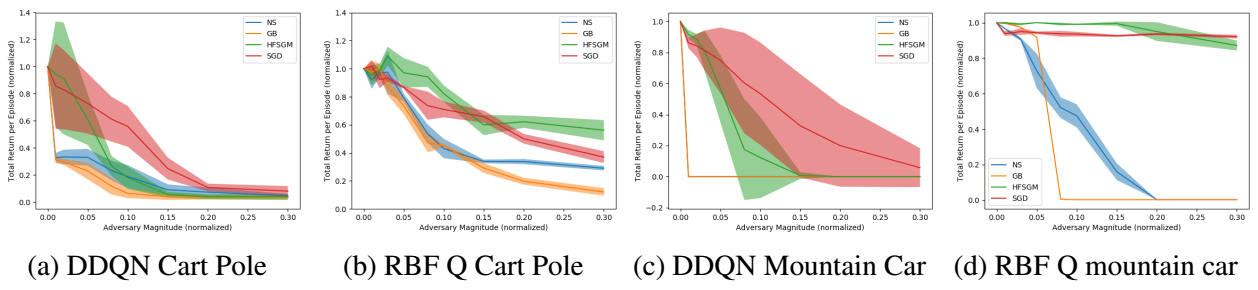
对抗攻击
绿色的方法是Huan等人的攻击效果,蓝色的为本文的简单攻击,黄色的为本文基于梯度的攻击,红色为基于SGD的攻击。可以看到,攻击的效果相对于Huang等人的方法有了很大提升。
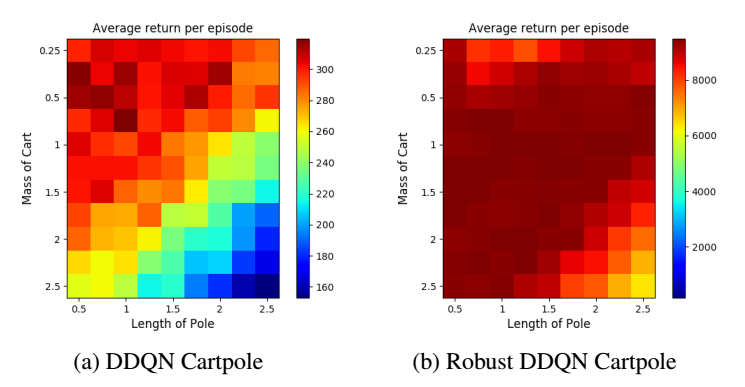
鲁棒训练
可以看到,经过鲁棒训练的智能体平均收益值提升很大。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!