论文链接:Curiosity-driven Exploration by Self-supervised Prediction, ICML 2017
一、问题
在稀疏的reward或者几乎没有reward的环境中,如何让agent更有效地对环境进行探索,是强化学习遇到的一个问题。而好奇心是解决这个稀疏reward问题的一个方法。好奇心驱动的工作如果放在强化学习的框架中来看,主要有两大类具体形式:
- 激励agent去探索更多的新状态(novel state);
- 激励agent去执行一些会减少自己对于未来不确定性的动作,或者可以反过来理解为去执行一些能增加自己对于未来的信息的动作。
这两个思想都非常好理解,几乎可以完全在人类的学习中找到映射。然而只考虑这两点则会出现一些问题,比如,对高维空间的环境进行预测本身非常困难,尤其是当前问题或者环境存在很多噪音的时候,这类驱动方法往往会导致agent被无关干扰物吸引。
二、解法
针对这些问题,本文提出了ICM (Intrinsic Curiosity Module)方法,思路就是去尽量减少噪音的影响。因为去激励agent去执行那些会降低自己对于未来不确定性的动作,必然涉及到要去预测某个动作会产生怎样的影响,所以本文的思路是只预测那些和当前动作有关的影响。也就是说当 agent执行一个动作或者随着timestep的进行,环境的变化有两大类:一类是由agent造成的;一类则是噪音,和agent如何选择动作无关。
本文的解决方法是将好奇心的reward建模成agent对于新状态在visual feature space中的预测与实际状态在visual feature space的表征的不同,同时利用self-supervised inverse dynamics model来帮助agent对特征空间进行状态特征的提取,并在面对新环境中进行fine-tuning。
ICM框架如下图所示:
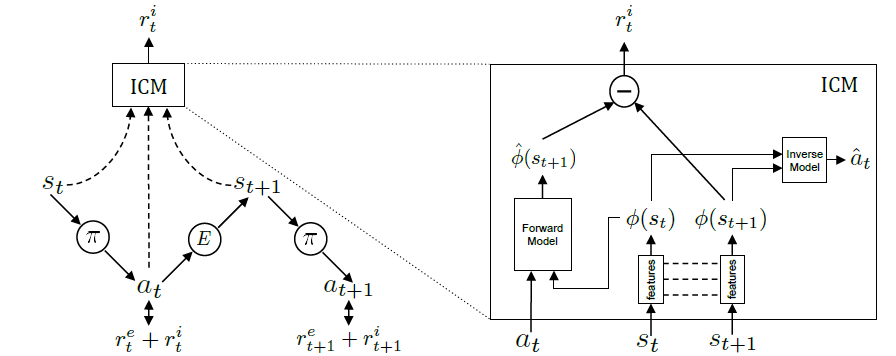
将intrinsic reward作为总的reward的一部分$r_{t}^{e}+r_{t}^{i}$,在RL训练中一起进行最大化:
\[\max _{\theta_{P}} \mathbb{E}_{\pi\left(s_{t} ; \theta_{P}\right)}\left[\Sigma_{t} r_{t}\right]\]预测误差作为intrinsic reward
设计intrinsic reward很大程度上与你想要解决的任务相关,这里想要解决的问题是video game,那么就要立足在video game获得state就是一张图片。一种很直接的想法就是:在状态$s$下,采用动作$a$,通过卷积与反卷积等结构来预测下一状态$s’$,通过预测出来的$s’$与实际的$s_{r}^{‘}$的误差作为agent的reward。然而,直接预测下一个状态$s’$其实存在一系列问题,比如预测每个pixel的颜色是一件很困难的事,稍微有些差别,prediction error就会变化的比较大,所以agent很容易被这样的信息误导,并没有达到探索的目的。此外图片中的信息其实非常丰富,比如在不同关卡的背景,亮度不同,但是本质的内含相近,关注这些额外的信息反而会影响在不同关卡中的泛化。总结来看,在state space中可以分成三种信息:
- agent可以控制,比如agent开枪射出子弹
- agent不可以控制的,但是对agent有实际影响的,比如怪物的移动
- 本质上无效的信息,比如agent走着走着,从白天变成黑夜,背景变黑了
其实我们真正关注的是第1和第2种信息,因为这两种信息才是本质上影响agent决策的信息,那么我们的curiosity reward应该建立在这两种信息上才会让agent更有效地探索学习。
Self-supervised prediction for exploration
Inverse Model提取state表征
那么如何提取state的有效信息呢?作者构造了一个Inverse Model,训练目标是根据当前state和下一个state估计中间采取的action。和前面预测state正好反过来。这种方法可以利用现有数据进行监督学习。为了争取估计action,CNN就需要能够提取图像中的有用信息,比如自身的位置变化,周围物体的变化,而对于图像中无关的信息则能自动忽略。所以作者用这种简单的方法就能训练出自动提取有效信息的model。具体来说,Inverse Model的训练方式如下:
- 建立模型根据当前state $s_{t}$和下一个state $s_{t+1}$预测中间采取的动作:$\hat{a}_{t}=g\left(s_{t}, s_{t+1} ; \theta_{I}\right)$
- 最小化预测动作与真实动作的loss:$\min_{\theta_{I}} L_{I}\left(\hat{a}_{t}, a_{t}\right)$
Forward Model预测下一时刻state表征
通过Inverse Model得到了对state space进行表征的方法,再根据Forward Model进行预测下一时刻state的预测,预测值与真实值得error就是intrinsic reward。具体来说,Forward Model的训练方式如下:
- 预测$t+1$时的state encoding:$\hat{\phi}\left(s_{t+1}\right)=f\left(\phi\left(s_{t}\right), a_{t} ; \theta_{F}\right)$
- 最小化预测状态encoding与真实状态encoding之间的loss:$L_{F}\left(\phi\left(s_{t}\right), \hat{\phi}\left(s_{t+1}\right)\right)=\frac{1}{2}\left|\hat{\phi}\left(s_{t+1}\right)-\phi\left(s_{t+1}\right)\right|_{2}^{2}$
- 计算intrinsic reward:$r_{t}^{i}=\frac{\eta}{2}\left|\hat{\phi}\left(s_{t+1}\right)-\phi\left(s_{t+1}\right)\right|_{2}^{2}$
最后我们可以将agent的学习目标定成:
\[\min _{\theta_{P}, \theta_{I}, \theta_{F}}\left[-\lambda \mathbb{E}_{\pi\left(s_{t} ; \theta_{P}\right)}\left[\Sigma_{t} r_{t}\right]+(1-\beta) L_{I}+\beta L_{F}\right]\]三、实验内容
在VizDoom和Super Mario Bros上进行了实验,对比了没有加入探索机制A3C、TRPO和加入VIME的一些RL算法。
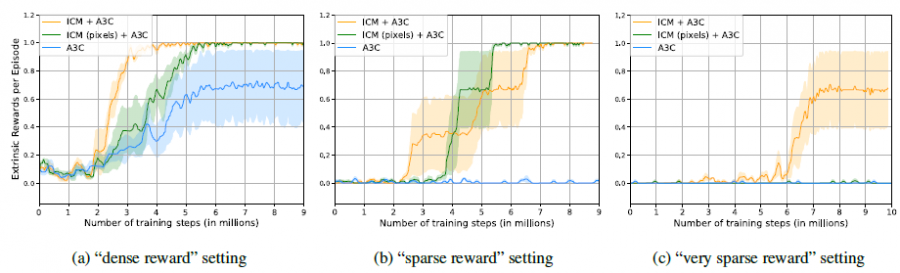
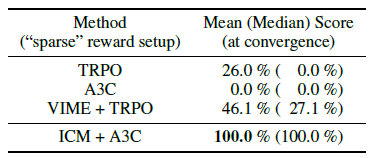
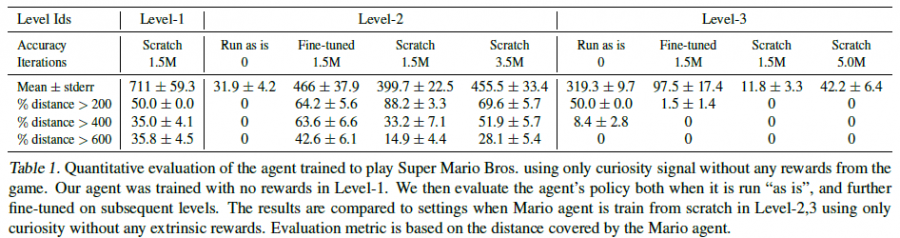
四、缺点
- Inverse Model的idea应用到其他大规模的问题上效果不好确定。因为并不是每一种环境都可以这样去进行熟悉,在复杂环境上预测state和action可能相当困难
- 对环境的熟悉程度不能仅通过预测state来评判,需要更丰富
五、优点
属于curiosity开山之作;Inverse Model的建立非常巧妙。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!