论文链接:Can Deep Reinforcement Learning solve Erdos-Selfridge-Spencer Games? ICML 2018
一、问题
深度强化学习的泛化性不好测试,因为总是在训练环境上做测试。本文提出使用一种Spencer’s attacker-defender game,可以用于验证强化学习的泛化性。除此之外,还利用这个环境对比了监督学习、多智能体学习与self-play等方法的表现。Spencer’s attacker-defender game可以通过下图得到解释:
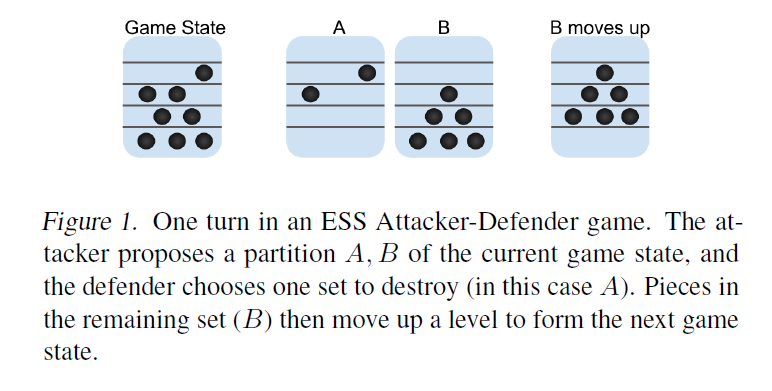
attacker-defender game包含两个玩家:移动碎片的攻击者和破坏碎片的防御者。比如,游戏具有一组从0到K层的楼层,并且在这些楼层上初始化了N个碎片。 攻击者的目标是至少使他们的碎片之一达到K层,而防御者的目标是在这发生之前销毁所有N枚碎片。在每个回合中,攻击者都会选择一个现存碎片的划分:$A$和$B$。 防守者选择其中一组进行破坏并从游戏中移除。另一组中的所有碎片均上移一层。 当一个或多个碎片达到楼层K,或者所有碎片都被破坏时,游戏结束。
二、解法
上述游戏具有如下设定和结论:
- Potential Function:给定游戏状态$S=\left(n_{0}, n_{1}, \dots, n_{K}\right)$,$n_{i}$为在$i$层的碎片数,该函数定义为$\phi(S)=\sum_{i=0}^{K} n_{i} 2^{-(K-i)}$。
- 考虑一个具有K层和N个碎片的游戏,该碎片放置在不同楼层上的任意位置,初始状态为$S_{0}$。如果$\phi(S_{0}) < 1$,防守者必胜;如果$\phi(S_{0}) > 1$,进攻者必胜。
- $\phi(S_{0}) < 1$时,防守者最优策略是摧毁$A$和$B$中Potential值更大的一组;$\phi(S_{0}) > 1$时,进攻者最优策略是划分两组Potential值$\ge 0.5$的$A$和$B$。但由于这种最优解需要探索的动作空间太大,本文提出了一种新的最优方法,即在这种设置下,存在$A$和$B$使得$A$包含的碎片所属楼层全部大于某值$l$,$B$包含的碎片所属楼层全部小于某值$l$。因此攻击者只要探索选取哪个楼层进行划分$A$和$B$即可。
三、实验内容
对于防守者的训练,设置进攻者为Disjoint Support策略(最优策略与次优策略并存的策略,绝大多数时候用最优策略,极少时候使用次有策略z作为探索),DQN优于PPO优于A2C。但是在泛化性测试时,在最优策略上训练的防守者智能体在与Disjoint Support策略进攻者对决时表现很差。本文认为可以通过与一个用learning方法训练的进攻者来对决训练,以解决这种过拟合问题。
对于进攻者的训练,使用上述对进攻者的动作设定与最优策略防守者训练,PPO和A2C远远优于DQN。在与这样的进攻者对决下训练出来的防守者,泛化性优于先前的防守者。
对于self-play(使用同一个神经网络来表征攻击者和防守者的参数),使用DQN训练,得到的防守者在与进攻者为Disjoint Support策略对战时,可以比上述的与程式化进攻者训练得到的策略胜率都高。self-play算法流程如下:

对于监督学习方法,RL方法总的做出正确选择的次数小于监督方法,但是在游戏里RL的表现更好,犯严重错误的次数也更少。这是因为RL具有预测未来的能力,而监督并没有。
四、缺点
暂无评价。
五、优点
对于游戏和算法的设计以及最优解有理论证明与实验验证,这种做研究的方法和态度是我理想中最好的样子;实验非常丰富,从多个角度全面研究了RL的表现、泛化性、长远规划等问题;
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!