论文链接:Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments, NIPS 2017
代码链接:github链接
视频链接:论文实验效果
一、问题
多智能体处于混合模式(合作-竞争)的情形下的问题,并以此提出了MADDPG算法,实质上就是对DDPG算法的一种延伸和扩展。现有算法的问题:
-
Independent Q-learning: 每个智能体都在随着训练而改变策略,导致整个环境的不稳定性。因此智能体存到replay buffer的经验都不能用。
-
Policy Gradient:梯度估计的方差高,尤其是多智能体环境下。理论证明,当只做一次采样的时候,算出来的梯度的方向与真正梯度的方向的夹角小于90(即梯度在正确的方向上的减少)的可能性是随着智能体数目上升而指数下降

二、解法
2.1 Multi-Agent Actor Critic
环境的设置有较强的通用性:(1)每个智能体在实际执行时只使用local observation; (2)不对环境建模;(3)不对智能体间的通信做显式建模。然而,既然在实际中不知道其他agent的信息,但是其他的agent的信息能够很好的帮助学习,很自然就会想:我们就在训练的时候使用这些信息,实际运用的时候的不用这些信息,那很自然就可以学习出一个更好的agent了。更进一步,我们想要在offline的时候利用更多的信息学习出一个拥有比较好policy的agent,但是为了能够在实际的设置中使用,这个agent的policy的输入与输出在训练与实际使用的时候应该一样,所以无法直接把额外的信息直接结合在policy的输入中。那么有一种想法就是这些额外的信息既然无法直接用,那么就拿来做更准确的梯度的估计,那么很直观的想法就是用Actor Critic结构。
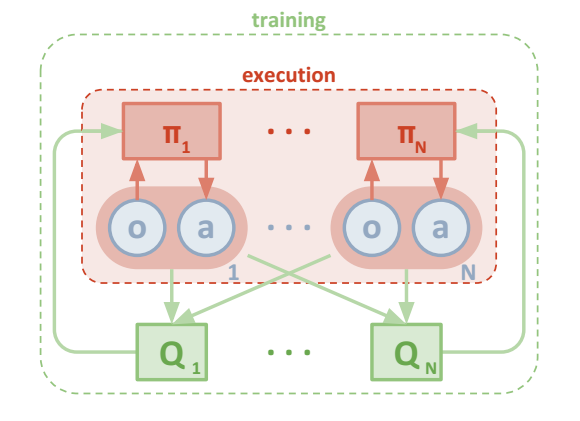
整体算法框架如下:每一个智能体使用自己独立的actor,通过自己观测状态$o$,输出确定的动作$a$,同时训练数据也只使用自己产生的训练数据,每一个agent同时也对应一个critic,但是该critic同时接收所有actor产生的数据,本文将其当做中心化的critic。这种中心化critic和普通的中心化critic不同的是,本文的critic存在N个(每个agent一个)。
Actor Critic的策略梯度公式为:\(\nabla_{\theta_{i}} J\left(\theta_{i}\right)=E_{s \sim p^{u}, a_{i} \sim \pi_{i}}\left[\nabla_{\theta_{i}} \log \pi_{i}\left(a_{i} \| o_{i}\right) Q_{i}^{\pi}\left(o_{i}, a_{i}\right)\right]\)
推广到多智能体设置下,Actor Critic的策略梯度公式则为:
\[\nabla_{\theta_{i}} J\left(\theta_{i}\right)=\mathbb{E}_{s \sim p^{\mu}, a_{i} \sim \pi_{i}}\left[\nabla_{\theta_{i}} \log \pi_{i}\left(a_{i} | o_{i}\right) Q_{i}^{\pi}\left(\mathrm{x}, a_{1}, \ldots, a_{N}\right)\right]\]推广到MADDPG下,即输出确定性动作,则策略梯度公式为:
\[\nabla_{\theta_{i}} J\left(\boldsymbol{\mu}_{i}\right) = \mathbb{E}_{\mathbf{x}, a \sim \mathcal{D}}\left[\left.\nabla_{\theta_{i}} \boldsymbol{\mu}_{i}\left(a_{i} | o_{i}\right) \nabla_{a_{i}} Q_{i}^{\boldsymbol{\mu}}\left(\mathbf{x}, a_{1}, \ldots, a_{N}\right)\right|_{a_{i}=\boldsymbol{\mu}_{i}}\left(o_{i}\right)\right]\]其中$i$为agent,$\boldsymbol{\mu}$为策略。Critic的更新为:
\[\mathcal{L}\left(\theta_{i}\right)=\mathbb{E}_{\mathbf{x}, a, r, \mathbf{x}^{\prime}}\left[\left(Q_{i}^{\mu}\left(\mathbf{x}, a_{1}, \ldots, a_{N}\right)-y\right)^{2}\right], \quad y=r_{i}+\left.\gamma Q_{i}^{\mu^{\prime}}\left(\mathbf{x}^{\prime}, a_{1}^{\prime}, \ldots, a_{N}^{\prime}\right)\right|_{a_{j}^{\prime}=\boldsymbol{\mu}_{j}^{\prime}\left(o_{j}\right)}\]其中$\boldsymbol{\mu’}$为target network策略。
2.2 Inferring Policies of Other Agents
知道其他agent的策略这个假设过于强,所以这里提出弱化该假设的方法:知道对手的action,不知道对手的policy。然后通过别人的observation和action来估计出别人的policy。所以可以采用极大似然估计来估计policy,另外加上一个entropy增加policy的不确定性:
\[\mathcal{L}\left(\phi_{i}^{j}\right)=-\mathbb{E}_{o_{j}, a_{j}}\left[\log \hat{\boldsymbol{\mu}}_{i}^{j}\left(a_{j} | o_{j}\right)+\lambda H\left(\hat{\boldsymbol{\mu}}_{i}^{j}\right)\right]\]使用这个估计出的别人的策略来更新Critic:
\[\hat{y}=r_{i}+\gamma Q_{i}^{\boldsymbol{\mu}^{\prime}}\left(\mathbf{x}^{\prime}, \hat{\boldsymbol{\mu}}_{i}^{\prime 1}\left(o_{1}\right), \ldots, \boldsymbol{\mu}_{i}^{\prime}\left(o_{i}\right), \ldots, \hat{\boldsymbol{\mu}}_{i}^{\prime N}\left(o_{N}\right)\right)\]2.3 Agents with Policy Ensembles
很多时候agent使用的策略只对当前的其他agent使用的策略有效,一旦其他agent稍微变化效果就变差,所以在这里我们对每个agent都训练$k$个不同的策略,然后在每次训练的时候就在这个策略集中随机挑选一个,那么这样就有可能能够学出$k$个不同的策略,但是在实际运用中,我们只使用一个policy,所以我们可以利用这$k$个策略来做权衡,学习出一个总的策略。对于每个sub policy单独采用MADDPG学习:
\[J_{e}\left(\boldsymbol{\mu}_{i}\right)=\mathbb{E}_{k \sim \operatorname{unif}(1, K), s \sim p^{\mu}, a \sim \boldsymbol{\mu}_{i}^{(k)}}\left[R_{i}(s, a)\right]\]因此策略梯度公式变为:
\[\nabla_{\theta_{i}^{(k)}} J_{e}\left(\boldsymbol{\mu}_{i}\right)=\frac{1}{K} \mathbb{E}_{\mathbf{x}, a \sim \mathcal{D}_{i}^{(k)}} \left[\left.\nabla_{\theta_{i}^{(k)}} \boldsymbol{\mu}_{i}^{(k)}\left(a_{i} | o_{i}\right) \nabla_{a_{i}} Q^{\boldsymbol{\mu}_{i}}\left(\mathbf{x}, a_{1}, \ldots, a_{N}\right)\right|_{a_{i}=\boldsymbol{\mu}_{i}^{(k)}}\left(o_{i}\right)\right]\]MADDPG算法流程如图:

三、实验内容
在多个环境上打败了DDPG、DQN等Independent learning方法。
四、缺点
- 每一个Critic需要观测到所有的agent的状态和动作,对于大量不确定agent的场景,不是特别实用
- 当agent数量特别多的时候,状态空间太过于巨大
- 每一个agent都对应了一个actor和一个critic,数量多的时候,存在大量的模型。
五、优点
- 对于集中训练分步执行的方法是一种完善
- 是多智能体环境下的开创性工作。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!