论文链接:Exploration by random network distillation, ICLR 2019
一、问题
本文的方法旨在解决在高维连续空间中对状态访问计数(count-based)。但由于是高维连续空间,这个计数更多地可以看做是密度估计。如果类似的状态之前访问得少,说明这个状态比较新奇,那么就给予比较高的intrinsic reward。文章用了一个比较机智的方法来快速地估计某个状态是不是之前出现的比较少。
二、解法
2.1 使用神经网络来作为状态新颖程度的估计
count-based exploration方法的目标是找到一种方法对于每一个状态都返回一个值,告诉我们它与之前见到过的状态有多少的相似程度。本文的方法基于一个观察:如果在神经网络训练中,如果有类似的数据出现在训练中,那么其预测误差将会显著减小。
对于状态$x$,用一个固定的随机参数的网络去给出任意一个给定的状态的函数$f(x)$,针对该值进行预测的方法就是训练一个神经网络$\hat{f}(x ; \theta)$,在训练样本上面最小化$|\hat{f}(x ; \theta)-f(x)|^{2}$。对于一个新的样本,如果预测误差小,说明这个样本在之前见过(或者见过类似的),那么就给予较低的奖励;反之,说明这个样本之前没怎么见过,于是给予较高的奖励。通过这样的方法可以鼓励智能体去探索未见过的状态。
这种设定下,我们一直保持更新的这个神经网络就相当于在维护的一个density estimator,我们可以随时知道一个新的状态与之前状态分布离得远不远。
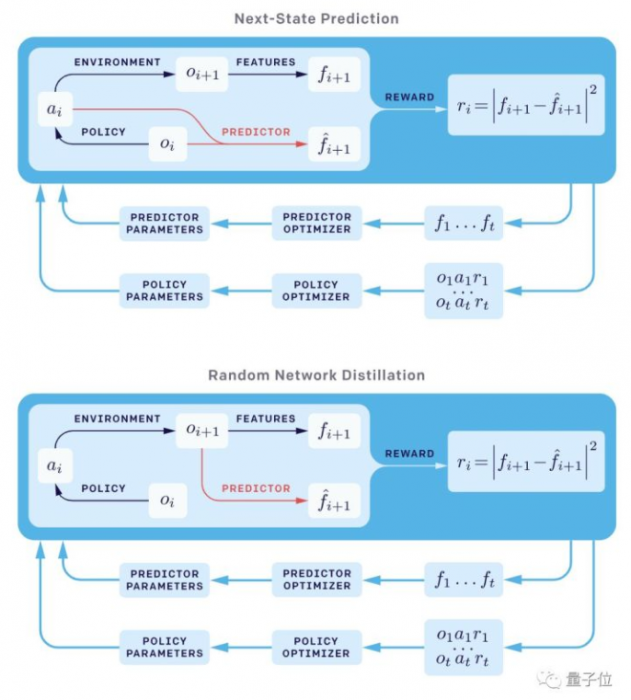
2.2 神经网络预测误差的构成
神经网络预测误差主要由以下四个部分构成
- 训练数据量和分布:如果类似的数据见得少,那么这种数据的预测误差大;这是我们希望利用的性质,而后面其他的误差来源都是我们不希望见到的,尽可能去避免它们。
- 目标拟合函数的随机性:预测有误差可能由于希望拟合的函数本身就有随机性;之前很多方法使用拟合的动力学模型来作为目标,然后用动力学模型预测出来的下一步状态的误差作为intrinsic reward。这样的目标随机性就很大,相应的内在奖励说不清楚是由于状态很新颖导致的,还是由于随机性导致的。在这里,就使用了一个确定性的函数$f(x)$来避免这个问题。
- 模型能力不够:有可能目标拟合函数太过复杂,以至于神经网络根本没可能拟合出来,即最好情况也会产生较大的预测误差。在这里,确定性函数$f(x)$也同样使用一个随机参数的神经网络来生成,避免了这个问题。
- 学习的过程导致:可能使用的优化方法不够好,导致会产生额外的预测误差。 通过这样的一些分析,我们大致了解了为什么神经网络的预测误差能够作为一个样本是否“眼熟”的衡量依据。文章还引用了一套理论来说明这里的预测误差等效于模型对于预测这个样本的uncertainty,也就等效于该样本与之前样本分布的“距离”。
2.3 与extrinsic reward相结合
- 对intrinsic reward来说,比较好的方法是做non-episodic的探索,即一个回合结束之后,相应的收益(return)还继续累计而不截断。否则,一旦智能体做出某个动作导致回合结束,那么其收益为0,会激励智能体更加保守而不是更加探索。
- 对于extrinsic reward来说,比较好的方法是做episodic的探索,因为如果把return做累计,智能体可能就不断地在游戏开始的附近刷点小分,然后“自杀”继续回到这个地方刷分。
对于内在奖励和外部奖励这两种不同的探索模式,作者认为同时训练两个价值函数$V=V_{E}+V_{I}$。其好处还在于两个价值函数能用不同的discount rate来训练。

三、实验内容
RND加持的算法打蒙特祖玛的复仇,智能体逃出了第一关的全部24个房间,成绩远远超过人类的平均分数 (4.7k) ,以及现有最前沿的算法。
四、缺点
暂无评价。
五、优点
这种通过蒸馏的方式来快速估计每个状态是否见过,非常巧妙,便于复现。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!