论文链接:Multiagent cooperation and competition with deep reinforcement learning, PLOS ONE 2017
github链接:论文环境与算法代码
视频链接:论文实验效果
一、问题
本文研究了将DQN算法扩展到多智能体设置下时,在合作或竞争环境下智能体的表现。
二、解法
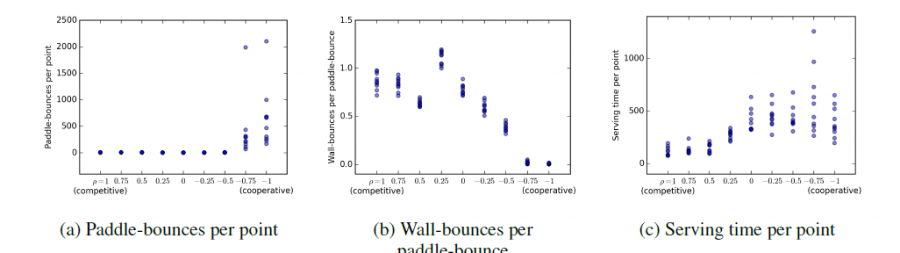
本文修改了Pong游戏的环境使之适配于两个智能体同时参与,每个智能体使用DQN算法独立训练,环境为完全可观察的。reward设计方面,对于完全竞争式环境,一方得分则另一方失同样的分;对于完全合作式环境,一方丢球则双方同时失分;对于竞争-合作并存式环境,则设置了一个奖励值范围来控制竞争与合作的成分。为了衡量不同环境设置下的智能体表现,设置了击球次数,反弹次数以及游戏重启时间作为衡量指标。
三、实验内容
对比了不同设置下上述的三个指标,在完全合作式环境下,智能体倾向于将球直接传给对方。在完全竞争式环境下,两个智能体都倾向于击败对方。在竞争-合作并存式环境下,不同指标情况如下:
四、缺点
- 受限于可用环境的约束,实验环境只有一个
- Q值高估的问题在多智能体设置下依旧存在
- 对于大规模多智能体问题来说,使用DQN训练可能并不适用
五、优点
- 在原始的得分指标不再有效的情况下,选取的三个衡量指标可以准确地反映出智能体的表现
- 首次验证了DQN可以作为较为复杂的视频游戏环境中多智能体设置下分布式学习的一种有效方法
赏
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
支付宝打赏
微信打赏
您的打赏是对我最大的鼓励!