论文链接:Unsupervised State Representation Learning in Atari, NIPS 2019
代码链接:github链接
一、问题
RL中通常通过使用来自奖励的信号通过端到端学习来学习状态的表征,但是这种方法通常效率很低,而且学到的表征可能包含很多对RL决策不产生影响的信息。本文借鉴自监督学习中的对比学习方法来构建Atari像素游戏的状态表征。
二、解法
本文的SpatioTemporal DeepInfoMax (ST-DIM)是在Deep Infomax的基础上进行改造升级的,原理图如下:
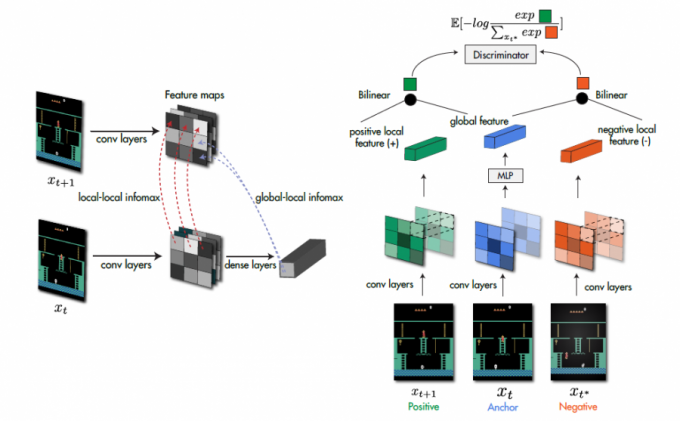
相对于Deep Infomax,本文的方法有两个不同:正负样本的选择与loss函数的选择。
2.1 正负样本的选择
本文表示学习方法依赖于在连续观察$x_{t}$和$x_{t + 1}$上基于互信息的下限来最大化对于互信息的估计值,因此对于时间$t$时的锚定数据observation $x_{t}$,正样本的为$t+1$时的$x_{t+1}$(即连续的观察),负样本为从同一个Minibatch随机采样得到的$x_{t^{*}}$(即非连续的观察)
2.2 loss函数的选择
相对于DIM的softmax来说,对应到图像样本中为N-way softmax损失,即InfoNCE loss。同时,考虑到对于信息量大的互信息,互信息的下界可能会比较宽松,在用于学习表征时,无法捕获数据中的所有相关特征。为了缓解这一问题,在global-local objective之外,本文的方法构建了多个较小的互信息目标,即local-local objective。这些目标已经被证明易于通过下限进行估计,也发现了它们在半监督学习的情况下效果很好。因此,本文的loss如下:
2.2.1 global-local objective
\[\mathcal{L}_{G L}=\sum_{m=1}^{M} \sum_{n=1}^{N}-\log \frac{\exp \left(g_{m, n}\left(x_{t}, x_{t+1}\right)\right)}{\sum_{x_{i}^{*} \in X_{n e x t}} \exp \left(g_{m, n}\left(x_{t}, x_{t^{*}}\right)\right)}\]其中评价函数为$g_{m, n}\left(x_{t}, x_{t+1}\right)=\phi\left(x_{t}\right)^{T} W_{g} \phi_{m, n}\left(x_{t+1}\right)$,$\phi_{m, n}$是$\phi$的中间层输出的local feature vector。
2.2.2 local-local objective
\[\mathcal{L}_{L L}=\sum_{m=1}^{M} \sum_{n=1}^{N}-\log \frac{\exp \left(f_{m, n}\left(x_{t}, x_{t+1}\right)\right)}{\sum_{x_{t}^{*} \in X_{n e x t}} \exp \left(f_{m, n}\left(x_{t}, x_{t^{*}}\right)\right)}\]其中评价函数为$f_{m, n}\left(x_{t}, x_{t+1}\right)=\phi_{m, n}\left(x_{t}\right)^{T} W_{l} \phi_{m, n}\left(x_{t+1}\right)$
三、实验内容
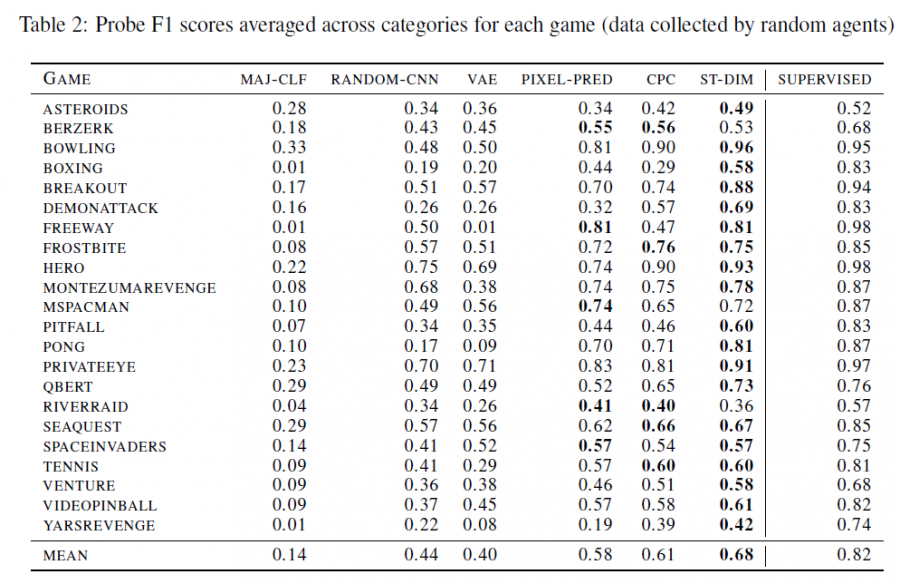
本文在Atari环境上构建了benchmark,使用F1 score评价从学习的表征中进行线性变换可以恢复所表征向量的程度,对比了ST-DIM与CNN、VAE、PIXEL-PRED、CPC等不同的表征方式,结果如下:
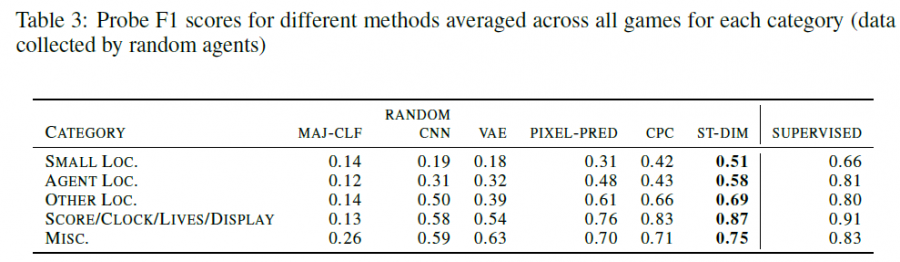
同时捕捉图像中关键的小型对象的能力也强于VAE等方法:
四、缺点
本文只是在图像的角度上做了状态表征,没有应用于RL中进行实际训练,RL agent只用来收集了自监督的训练样本。
五、优点
- 首个将Contrastive Learning引入RL中进行state representation的工作
- 相比于用CNN处理的像素画面,这种做法可以更多地提取有用的抽象信息,忽略无关的像素级别的细节
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!